A perceptron is the most basic unit in a neural network. It’s essentially the building block of a network—a single artificial neuron. It is a mathematical model inspired by how biological neurons work. It takes multiple input values, applies weights to them, adds them up, and then passes the result through a threshold function to produce an output.
These weights are crucial. They are determined through training and define how important a certain input is for triggering the perceptron.
For example, if the task of a perceptron is to determine whether a matrix contains the letter “A”, it is trained to weight only the pixels that form an “A” as important.
Below is a very simplistic version of a trained perceptron that has learned to weight the last row in the input to detect an “A”. The weights were adjusted to reflect that the uppermost pixel should be off, and all others should be on.
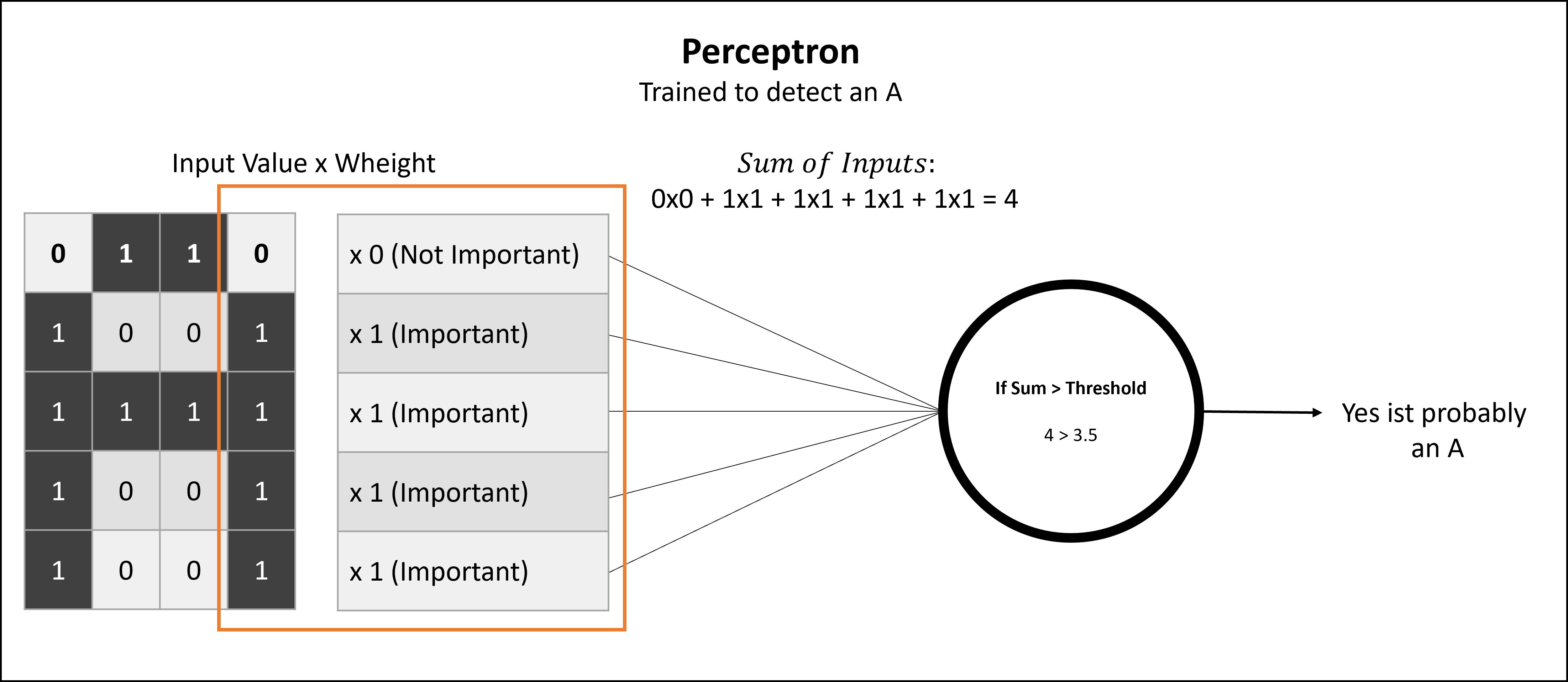
Each input is multiplied by a weight that reflects its importance. The perceptron adds up these weighted inputs and checks if the total exceeds a certain threshold (also determined through training). If it does, the perceptron “fires” and outputs a 1; otherwise, it outputs a 0. By adjusting the weights during training, the perceptron learns to recognize patterns in the input data.
This is usually done for every point in the input matrix. The sum of the inputs is often biased in more complex models, but that’s beyond the scope of this post. To see the full formula and a deeper explanation, see the inspiration blog post or the source code mentioned at the end under “Sources”.
The goal in my project was to detect the letter “F” in bit images — simple images made up of black and white pixels, or 1 and 0 values.
Basically, this is a very simple form of Optical Character Recognition (OCR). The same concept, on a more complex scale, allows your printer or scanner to make handwritten letters computer-readable and searchable.
Even when characters were slightly distorted, misaligned, or missing parts, the perceptron could still recognize them correctly. That’s where its true strength lies.
Traditional computers work in strict binary: 0 or 1, with no in-between. That makes fuzzy or imperfect input a challenge.
The perceptron changes that by introducing a mathematical way to judge how close a pattern is to a known one—not just whether it’s an exact match. It outputs a value that can be interpreted as a confidence level, giving the system the flexibility to handle imperfect or partial data more like a human would.
The program starts by initializing:
Started Training:
Epoch: True
Error: True
Trainingsloop is about to Start
Press any Key to continue...After that, it starts training. The training function is a whole topic in itself.
There are challenges like local minima, where the training gets stuck. (Imagine a ball rolling downhill and getting stuck in a high-up mountain lake—a local minimum—where ideally you would like it to go even lower.) The selection of training data is another deep topic on its own.
Luckily, as you can see during training, the error is quickly reduced in this simple model:
The current Error is: 0,3293899782001972 Rounds to Go: 995540
[...]
The current Error is: 0,31943007558584213 Rounds to Go: 995353
[...]
The current Error is: 0,3084575794637203 Rounds to Go: 995132
[...]
The current Error is: 0,29952602833509445 Rounds to Go: 994940
[...]
The current Error is: 0,289956571534276 Rounds to Go: 994717
[...]
The current Error is: 0,00018721475316851866 Rounds to Go: 20
[...]
The current Error is: 0,00018721475680649746 Rounds to Go: 0Then the determined weights for each point in the matrix for detecting the letter “F” are printed. Pixel 6, for example, has a strong negative weight, meaning its presence makes it unlikely to be an “F”. Pixel 9, on the other hand, appears to be quite important for identifying the letter “F”.
The Weights are:
Weight 0 is -1,3618933E-05
Weight 1 is 2,097018E-05
Weight 2 is 2,097018E-05
Weight 3 is 6,0882056E-05
Weight 4 is -4,732247E-05
Weight 5 is -1,931996E-05
Weight 6 is -8,6707005E-05
Weight 7 is 5,4207762E-06
Weight 8 is 6,4213586E-05
Weight 9 is 7,356823E-06
Weight 10 is -9,254295E-05
Weight 11 is -4,306942E-05
Weight 12 is -8,783184E-05
Weight 13 is -8,602366E-05
Weight 14 is 3,520834E-06
Weight 15 is 3,5096586E-05
Weight 16 is 6,506657E-05
Weight 17 is -5,9042144E-05
Weight 18 is 3,349005E-06
Weight 19 is -1,4003689E-05
Weight 20 is 0,99979883Below you can see all the letters the perceptron was trained with:
11
1 1
1111
1 1
1 1
111
1 1
111
1 1
111
111
1
1
1
111
111
1 1
1 1
1 1
111
1111
1
111
1
1111
1111
1
111
1
1
1111
1
1 11
1 1
1111
1 1
1 1
1111
1 1
1 1
111
1
1
1
111
1111
1
1
1 1
11
1 1
1 1
11
1 1
1 1
1
1
1
1
1111
1 1
1111
1 1
1 1
1 1
1 1
11 1
1111
1 11
1 1
11
1 1
1 1
1 1
11
111
1 1
111
1
1
11
1 1
1 1
1 11
111
111
1 1
111
1 1
1 1
111
1
11
1
111
1111
1
1
1
1
1 1
1 1
1 1
1 1
11
1 1
1 1
1 1
1 1
1Now we finally enter the prediction stage, where we throw random patterns at the perceptron and see whether it classifies them as the letter “F”:
Predicting is a 'F' (yes = 1, no = 0) for the following pattern:
11
1 1
1111
1 1
1 1
The Prediction is:
No, it is no F
The Dotpoint is 5,512309E-06 it Activates at: 7,118798E-05
Predicting is a 'F' (yes = 1, no = 0) for the following pattern:
11
1
111
1 1
111
The Prediction is:
No, it is no F
The Dotpoint is 5,4214746E-05 it Activates at: 7,118798E-05
Predicting is a 'F' (yes = 1, no = 0) for the following pattern:
1 11
1
11
1
The Prediction is:
Yes, it is a F
The Dotpoint is 0,0002287358 it Activates at: 7,118798E-05Success!
The project can be found at Github Perceptron Repo
Basic inspiration and explanations were taken from: James McCaffrey Blog Post
Additionally, this article in German is a great way to get started with a lot of detail and has been used too Suplement the Post above.